Remove Duplicate Characters or Words in Excel
When working with text data in Excel, it is common to encounter duplicate characters or repeated words within a single cell. This often happens with imported data, user input, tags, or product descriptions. Cleaning these duplicates can improve readability, ensure data consistency, and make further analysis more reliable.
In this guide, we will walk you through several effective methods to remove duplicate characters or words in Excel. These include built-in formulas, a faster batch solution using Kutools for Excel, and customizable VBA functions. You can choose the most suitable method based on your Excel version, technical level, and workflow needs.

Remove duplicate characters in Excel
Removing duplicate characters means keeping only the first occurrence of each character within a cell (for example, converting "aabbcc" → "abc"). Below are three practical methods to achieve this.
Using Excel formula
If you are using Excel for Microsoft 365 or Excel 2021 and later, you can remove duplicate characters using dynamic array formulas. This method is fully built-in and automatically updates when your source data changes, making it ideal for users who prefer formula-based solutions.
Steps:
- Select a blank cell where you want to display the result (for example, D2).
- Enter the following formula:
=TEXTJOIN("",,UNIQUE(MID(A2,ROW(INDIRECT("1:"&LEN(A2))),1))) - Press Enter to get the result.
- Drag the fill handle down to apply the formula to other cells if needed.
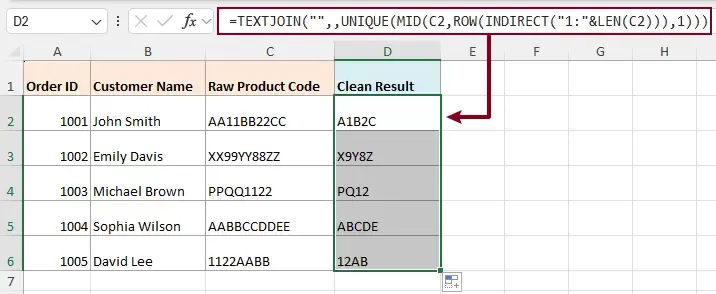

How the formula works:
- MID extracts each character from the text
- ROW + INDIRECT generates character positions
- UNIQUE removes duplicates
- TEXTJOIN combines the result back into a string
- This method only works in Excel 365 / 2021 or later
- If you see #NAME?, your version may not support these functions
Using Kutools for Excel in bulk
If you want to avoid complex formulas and need a faster, more user-friendly approach—especially for large datasets—Kutools for Excel provides a convenient way to remove duplicate characters in bulk.
Kutools for Excel - Packed with over 300 essential tools for Excel. Make Excel tasks faster, easier, and more efficient. Download now!
Steps:
- Select the range of cells where you want to remove duplicate characters.
- Go to Kutools > Text > Remove Characters.
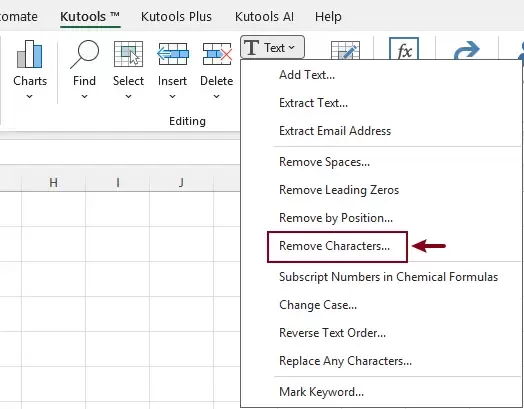
- In the Remove Characters dialog box, only check the Duplicated characters option. Click OK.
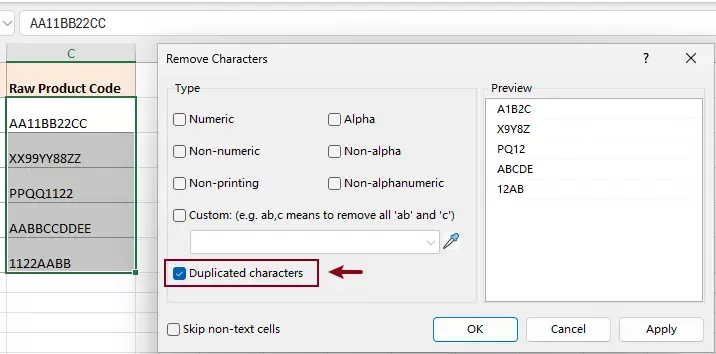


Result:
All duplicate characters in each selected cell are removed instantly, keeping only the first occurrence.
Advantages:
- No formulas or coding required
- Works in all Excel versions
- Supports batch processing
- Simple and intuitive interface
- Saves significant time for large datasets
Kutools for Excel - Supercharge Excel with over 300 essential tools, making your work faster and easier, and take advantage of AI features for smarter data processing and productivity. Get It Now
Using user-defined function
If your Excel version does not support dynamic array formulas, or if you prefer a reusable custom solution, you can use a VBA user-defined function (UDF) to remove duplicate characters.
Steps:
- Press Alt + F11 to open the VBA editor.
- Click Insert > Module.
- Paste the following code:
VBA code: Remove duplicate characters
Function RemoveDupes1(pWorkRng As Range) As String 'Updateby Extendoffice Dim xValue As String Dim xChar As String Dim xOutValue As String Set xDic = CreateObject("Scripting.Dictionary") xValue = pWorkRng.Value For i = 1 To VBA.Len(xValue) xChar = VBA.Mid(xValue, i, 1) If xDic.Exists(xChar) Then Else xDic(xChar) = "" xOutValue = xOutValue & xChar End If Next RemoveDupes1 = xOutValue End Function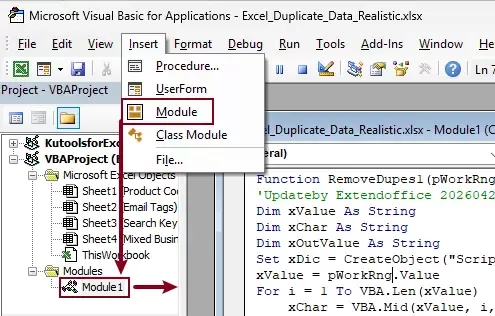
- Press Alt + Q to close the VBA editor and return to Excel.
- In a blank cell where you want to display the result, enter the following formula:
=RemoveDupes1(C2)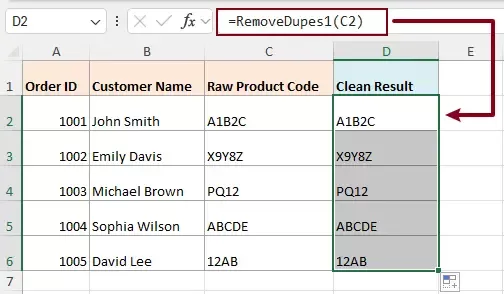


- Macros must be enabled
- The function only works in the current workbook
Additional: Remove duplicate words with user defined function
In some cases, your data may contain repeated words instead of characters, such as:
You may want to keep only unique words while preserving their order.
This method allows you to remove duplicate words based on a delimiter such as comma, space, or semicolon.
Steps:
- Press Alt + F11 to open the VBA editor.
- Click Insert > Module.
- Paste the following code:
VBA code: Remove duplicate words
Function RemoveDupes2(txt As String, Optional delim As String = " ") As String Dim x With CreateObject("Scripting.Dictionary") .CompareMode = vbTextCompare For Each x In Split(txt, delim) If Trim(x) <> "" And Not .exists(Trim(x)) Then .Add Trim(x), Nothing Next If .Count > 0 Then RemoveDupes2 = Join(.keys, delim) End With End Function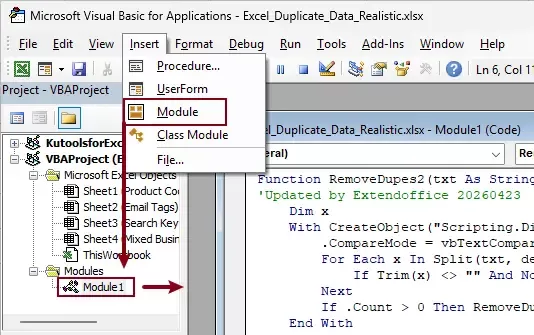
- Press Alt + Q to close the VBA editor and return to Excel.
- In a blank cell where you want to display the result, enter the following formula:
=RemoveDupes2(A2,",") - Press Enter to get the result, then drag the Fill Handle down to apply the formula to other cells.
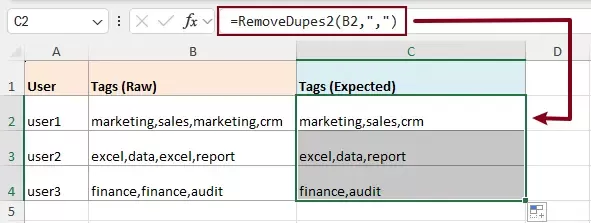


- In this formula, you can replace "," with other delimiters like " " or ";"
- Works best when data is consistently formatted
- Multiple delimiters may require customization
Conclusion
Removing duplicate characters or words in Excel can be achieved in several ways, depending on your needs and Excel environment.
- Use Excel formulas if you prefer a built-in and dynamic solution (Excel 365/2021).
- Use Kutools for Excel if you want a fast method for batch processing without formulas.
- Use VBA functions if you need flexibility or are working with older Excel versions.
Each method has its own advantages, and the best choice depends on your workflow, technical comfort, and data complexity. For most users handling large datasets, a tool like Kutools can significantly simplify the process and improve efficiency.
Best Office Productivity Tools
Supercharge Your Excel Skills with Kutools for Excel, and Experience Efficiency Like Never Before. Kutools for Excel Offers Over 300 Advanced Features to Boost Productivity and Save Time. Click Here to Get The Feature You Need The Most...
Office Tab Brings Tabbed interface to Office, and Make Your Work Much Easier
- Enable tabbed editing and reading in Word, Excel, PowerPoint, Publisher, Access, Visio and Project.
- Open and create multiple documents in new tabs of the same window, rather than in new windows.
- Increases your productivity by 50%, and reduces hundreds of mouse clicks for you every day!
All Kutools add-ins. One installer
Kutools for Office suite bundles add-ins for Excel, Word, Outlook & PowerPoint plus Office Tab Pro, which is ideal for teams working across Office apps.
- All-in-one suite — Excel, Word, Outlook & PowerPoint add-ins + Office Tab Pro
- One installer, one license — set up in minutes (MSI-ready)
- Works better together — streamlined productivity across Office apps
- 30-day full-featured trial — no registration, no credit card
- Best value — save vs buying individual add-in
Table of contents
- Remove duplicate characters in Excel
- Using Excel formula
- Using Kutools for Excel in bulk
- Using user-defined function
- Remove duplicate words in Excel
- The Best Office Productivity Tools
Kutools for Excel
Brings 300+ powerful features to streamline your Excel tasks.
- ⬇️ Free Download
- 🛒 Purchase Now
- 📘 Feature Tutorials
- 🎁 30-Day Free Trial